Windows Compression API
From time to time, security software (read: hacking tool) needs to send blobs of data around. It’s nice to keep those blobs as small as possible, so compression is useful. While building infrastructure in EvilVM, I want to live off the Win32 land as much as I can, but compression has been a difficult problem. I don’t want to write my own routines (compression algorithms aren’t the most fun to write and debug), and the code would be costly in terms of size.
Lots of hacking tools just include zlib and call it good, but there’s no C-based foundation in EvilVM. It’s made from x86_64 whole cloth, as it were, so it needs a lighter solution. This blog post is about how I can make use of the Win32 Compression API, which has been around since Windows 8 or so. I had to solve several interesting problems along the way, so I hope you enjoy the read.
My first application that needed compression was taking screenshots. A full-size framebuffer in the raw is often 5-10MB, depending on screen resolution. Even if I convert it to grayscale or down-sample it, it’s still pretty big. I really wanted to compress my images, and throwing in a JPEG or PNG encoder is similarly challenging when I’m trying to avoid C libraries and keep everything small.
The compression API presents a beautiful interface. You:
- Create a compressor object (CreateCompressor)
- Tell it to compress some data (Compress)
- Clean up your compressor (CloseCompressor)
With the C FFI in EvilVM, it’s about 30 lines of code to wrap up a complete buffer compression utility (way shorter than implementing DEFLATE myself or something crazy!). You can read it if you’re not afraid of Forth here.
The challenges start when you try to decompress, especially in a non-Windows environment (like my server that runs in Linux). The compression API doesn’t use common algorithms, but rather some Microsoft-ified variations on classic themes. Supposedly the MSZIP algorithm is similar to DEFLATE, and LZMS is analogous to LZMA, but they have their own twists. So I can easily compress my data and send it to the server, but decompression is not so simple.
I had the thought that I could just keep a Windows box handy, and write a little service that takes a compressed buffer, decompresses it, and returns the result. But that’s crazy – I should be able to do this in Linux, right? So I went looking for implementations of the special MS compression routines.
Unfortunately, there isn’t much. I found a few scattered on Github, of differing levels of maturity, and ultimately not useful for me because I couldn’t get them to decompress the actual blobs I was getting from the Compress function.
Then I found wimlib, which is a very mature, and well-done library for extracting files from WIM archives, maybe CAB files, and some other Microsoft formats. It includes decompressors for the XPRESS and LZMS algorithms, which are supported by the compression API. Though promising, I tried running the example decompressor, but to no avail.
:) atlantis examples gcc -o decompressfile decompressfile.c -lwim
:) atlantis examples ./decompressfile
Usage: ./decompressfile INFILE OUTFILE
:( 2 atlantis examples ./decompressfile ~/Projects/evilvm/foo.lzms foo.dat
Failed to create decompressor: The compression type was unrecognized
Here’s what the LZMS-compressed blob looks like (at least, part of it anyway):
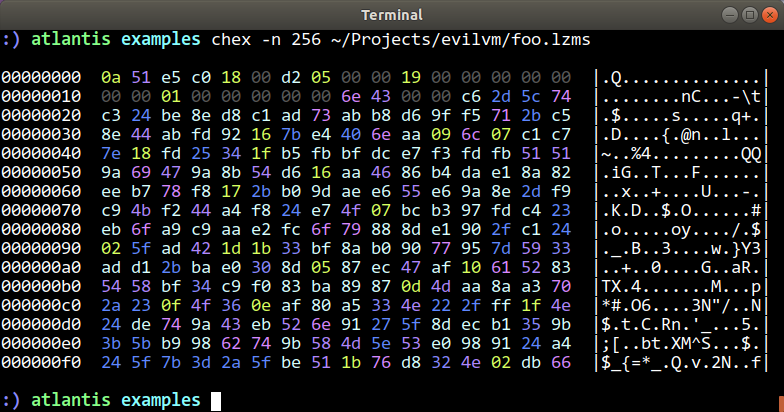
Comparing the initial contents of the file with how the decompressfile.c program was written suggested that the example code was not designed to decompress actual blobs from the compression API. It’s just designed to pair with the compressfile.c example, and the two collaborate with a certain binary format so that the wimlib API functions can be observed.
In fact, when I looked at the documentation in the lzms_decompress.c file, I saw this disheartening comment:
This decompressor only implements “raw” decompression, which decompresses a single LZMS-compressed block
Alas, I was not using the “raw” mode, and if I did it would involve more complex management of the compression process. Probably not prohibitive, but I really liked the idea that I could just Compress() a buffer and hand it off to the EvilVM server.
Per the documentation, the decompression routine for wimlib expects to be given certain information for each block of compressed data:

I need to know the compressed size and uncompressed size of each block. This information precedes each block in the tacit format implemented in compressfile.c and decompressfile.c. But it didn’t match what I saw as the output from the Microsoft functions. I needed to look a little deeper into the blob I was getting back from the compression API.
Look back at the hexdump from before. Notice that there is a series of fields – we’ll assume DWORDs for now, until we know better. I saw a couple things that stood out to me:
Offset Value Notes
0x0000 0xc0e5510a No idea
0x0004 0x05d20018 0x5d20 is pretty close to my compressed size (what's 0x18 for?)
0x0008 0x00190000 1638400, which is 1600x1024 pixels (my uncompressed size!)
0x000c 0x00000000 No idea
0x0010 0x00010000 64KB, the default compression chunk size
0x0014 0x00000000 No idea
0x0018 0x0000436e Not sure about this either...
0x001c+ ... Lots of high-entropy data
The fact that I could see my uncompressed size (which I knew because I generated the data) in there was really encouraging. Also, seeing the chunk size (and that it would change if I set a different chunk size when compressing data) made me think I might have what I need.
But how does the chunk size relate to compressed / uncompressed sizes? I naively attempted calling the wimlib decompression function with the whole blob and specifying the full buffer’s uncompressed size. Alas, and just as the documentation would suggest, this didn’t work because it expects to receive only one block at a time.
The wimlib example code stores both the uncompressed and compressed size before each block. So I thought, maybe the 0x436e value was the compressed size, and I could assume that all blocks will uncompress to the 64KB chunk size (except the last one, which would be whatever bytes were needed to fill up the total uncompressed length)…
So the high-entropy data starts at offset 0x1c. What’s 0x436e bytes beyond that? Let’s see what happens around offset 0x438a:
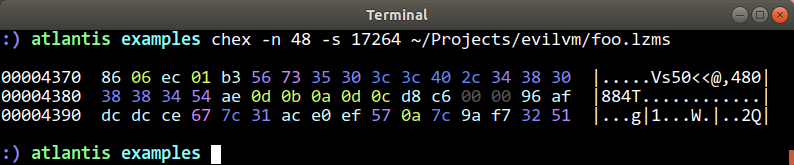
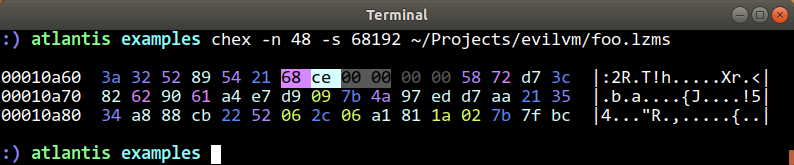
At 0x438a we have what looks like it could be another DWORD (those suspicious double NULL bytes are a clue). Might that be a prefix indicating the compressed size of the next chunk? If so, the chunk starts at 0x438e, and would go for 0xc6d8 bytes, putting the next chunk at 0x010a66:
And so on, it seemed like these were definitely length-delimited blocks of compressed data. And the assumption that each of them should uncompress to exactly the chunk size (64KB) seemed pretty safe. So I wrote up a short decoder that just reads in one of these compressed blobs, pulls out the chunk size, and extracts each chunk in turn to attempt decompression. You can find this file here in the EvilVM repo. Running it turned up this happy result:
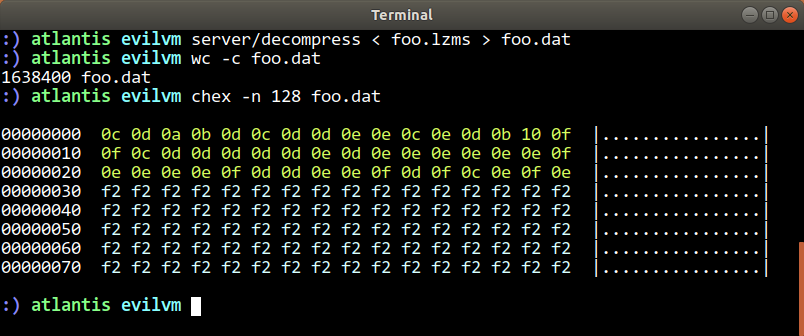
And that looks an awful lot like the 8-bit grayscale conversion of my screenshot that I started with. So this completed what I needed to compress data on the EvilVM agent side, send it to the server, and decompress it there for post processing. A very happy result!
Conclusion
It turns out that the LZMS compression algorithm is really nice. After playing with a lot of options, I ended up choosing a 3-3-2 RGB color space representation for my screenshots. I send that bitmap data directly through Compress() with a big block size, and I’m beating both JPEG and PNG file sizes right off the bat. It’s like a “poor man’s PNG”, only it’s actually better, so it’s a total win.
The Forth code to do compression turns out to be really short (read it here if you like), and for now my server (written in Ruby) just pipes the data through the C program I linked above. I may consider writing a Ruby wrapper for the wimlib calls, so that I can get rid of that external program, but for now it’s working quite well.